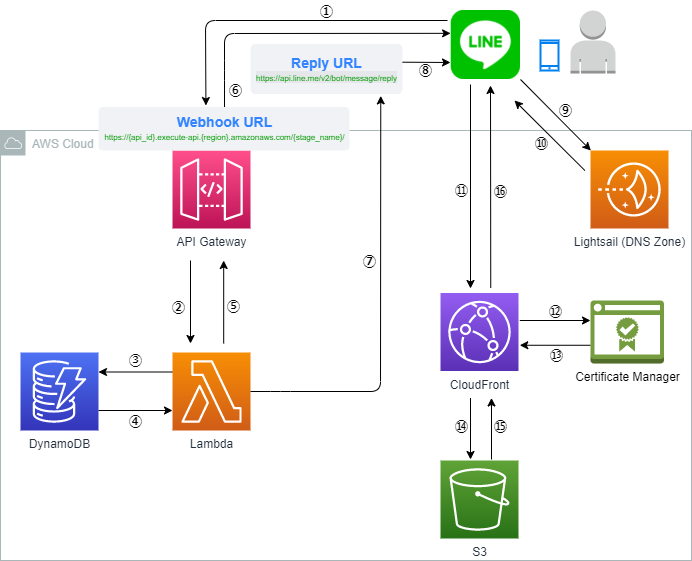
LINE ChatBot 制作 番外編② AWS DynamoDBにデータを一括投入
こんにちは、KimYasです。
今回は、LINE ChatBot 制作で使用したデータベース、"DynamoDB" に初期データを一括投入する方法について解説していきます。
DynamoDB実装の手順はこちらの記事で解説していますので、そちらも合わせてご覧ください。
それでは早速いきましょう!
CSVファイルをDynamoDBにインポート
今回参考にしたのは、こちらのAWS公式ブログです。
ブログ内でも述べられている通り、DynamoDBにデータを投入する方法には次の手法が考えられます。
- AWS マネジメントコンソールにて、手動で一件ずつ入力する。
- AWS CLIにて、JSON形式のデータをロードする。
- AWS Data Pipelineにて、S3からデータをインポートする。
しかし、これらの方法は費用や手間がかかることから、スマートな方法ではないとされています。
そこで、AWSではCSVファイルを簡単にDynamoDBに取り込む方法を確立しました。
具体的には、S3にアップロードされたCSVファイルを、Lambda関数を実行することによりDynamoDBに取り込みます。
しかも、必要なS3, Lambda, DynamoDBリソースは、AWSが用意してくれているCloudFormationテンプレートから簡単に作成できます。
それでは、実際の操作手順を見ていきましょう。
CloudFormationでリソース作成
まずはこちらのGitHubリポジトリから、"CSVToDynamo.template" というCloudFormationテンプレートファイルをダウンロードします。
さて、早速ここで一点注意です。
このテンプレートファイルをそのまま用いてもリソースは作成できるのですが、デフォルトではDynamoDBのパーティションキーが "uuid" という名前で作成されてしまいます。
そこで、その部分だけ自分好みのパーティションキー名に変更しておきましょう。
具体的には、以下のテンプレートファイルの一部をご覧ください。
…(中略)…
,
"Resources": {
"DynamoDBTable":{
"Type": "AWS::DynamoDB::Table",
"Properties":{
"TableName": {"Ref" : "DynamoDBTableName"},
"BillingMode": "PAY_PER_REQUEST",
"AttributeDefinitions":[
{
"AttributeName": "uuid",
"AttributeType": "S"
}
],
"KeySchema":[
{
"AttributeName": "uuid",
"KeyType": "HASH"
}
],
"Tags":[
{
"Key": "Name",
"Value": {"Ref" : "DynamoDBTableName"}
}
]
}
},
…(中略)…この "uuid" という箇所を、自分が望むパーティションキー名に変更しましょう。
私の場合はテーブル設計上、ポケモンの名前毎に一意のデータを定義していることから、"PokemonName" に変更しました。
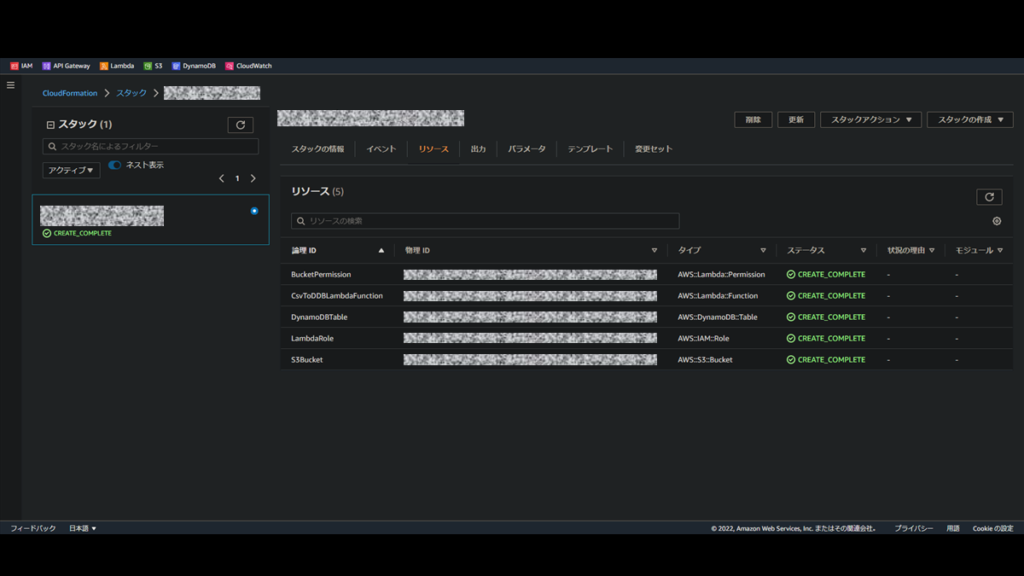
それではこのテンプレートファイルを用いて、CloudFormationからリソースを作成していきます。
操作は公式ブログに沿って進めていきます。
CloudFormationのスタックを作成してしばらく待ち、各リソースのステータスが "CREATE_COMPLETE" になれば成功です。
CSVファイル作成
投入するCSVファイルの中身は、私の場合はこんな感じでExcelで作成し、最後にCSVファイルとして保存しました。
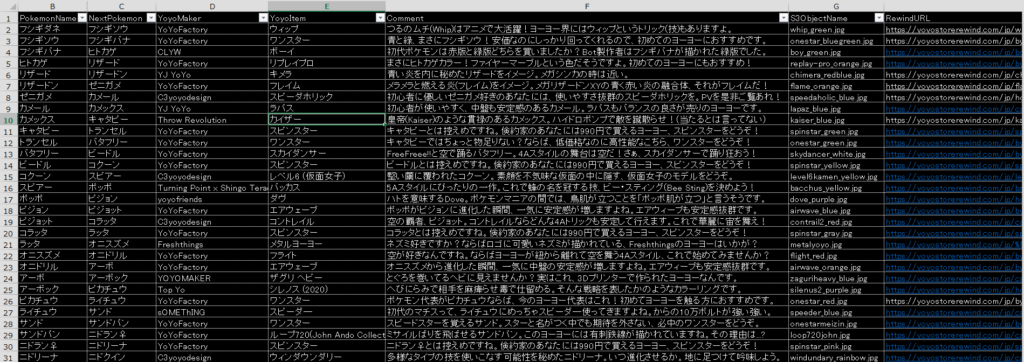
注意点として、CSVファイルの先頭列は必ずDynamoDBのパーティションキーと同じにしてください(上図では"PokemonName")。
そうしなければ、Lambda関数が上手くデータを読み込めないようです。
CSVファイルをS3にアップロード
それではCSVファイルを投入していきましょう。
といってもCSVファイルはDynamoDBに直接入れるのではなく、S3に格納します。
その理由は、あくまでもこの一連の作業の仕組みは、
- CSVファイルがS3バケットにアップロードされる。
- S3バケットへのファイル追加をトリガーにして、Lambda関数が起動する。
- Lambda関数がCSVファイルのデータをDynamoDBに書き込む。
というものだからです。
一見、どこか回りくどい方法に見えますが、やっていることはシンプルですね。
ということで、CloudFormationで作成されたS3バケットにコンソールからアクセスし、CSVファイルをアップロードします。
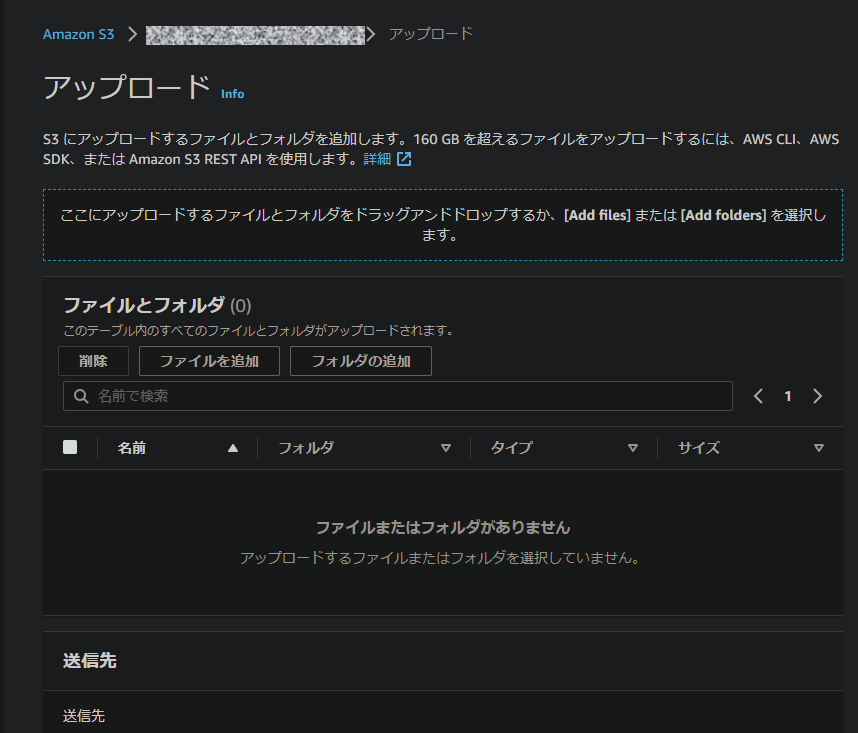
しばらく待ってからDynamoDBを確認すると、無事にデータが投入されていました。
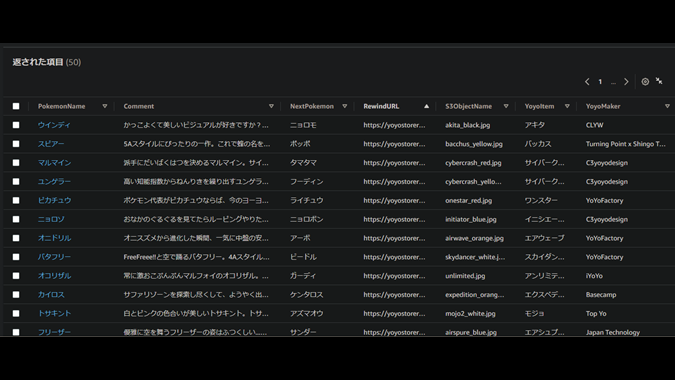
ちなみに今後、投入したデータに変更を加えたい場合が出てくるかもしれません。
少しの修正なら直接DynamoDB上で手を加えても良いですが、大きく変更する場合は面倒ですよね。
その時は、投入元のCSVファイルをローカルで修正し、同じファイル名で再びS3にアップロードすればOKです。
これにより、各項目の属性値が、新たにアップロードしたCSVファイルの属性値で更新されます。
(ただし、「旧ファイルにはあるが新ファイルには無い項目」は反映されません。
したがって、項目の削除を大幅に伴うような変更をしたい場合は、一度DynamoDBのデータをリフレッシュしてからの方が良いでしょう。)
エラー発生事例 DynamoDBに反映されない
手順通りに進めれば基本的にはできるはずですが、いくつか私が躓いた箇所をご紹介します。
当初、S3バケットにCSVファイルを投入しても、DynamoDBにデータが反映されませんでした。
自身の作業やログを振り返ってもCloudFormationによるリソース作成が完了する時点までは問題がなさそうだったため、それ以降の作業に不都合があったと予測を立てました。
そこから色々と調べてみると、Lambda関数のCloudWatchログに次のような記述を見つけました。
[ERROR] UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 63: invalid start byteこれは、「文字コード "utf-8" の設定でCSVファイルを読み取ろうとしたが失敗した」という旨のことを言っています。
ここでハッとしました。「もしかして、ExcelからCSV形式で保存するのがマズかったのでは…?」と。
実際、その通りでした。
どうやらExcelファイルをCSVとして保存すると、デフォルトでは文字コードがANSI(SHIFT-JIS)で保存されるようです。
それが原因となり、Lambda関数は文字を正しく読み取ることができず、エラーで止まってしまったという訳です。
対策は簡明で、文字コードをutf-8としてCSVファイルを保存すればOKでした。
ただ、私のExcelのバージョンは古いためか直接utf-8で保存できないため、以下の手順で文字コード変換しました。
- .xlsxファイルを.csvファイルとして一旦保存する。(この時点で文字コードはANSI)
- .csvファイルをメモ帳で開く。
- 名前を付けて保存から、文字コードutf-8を指定して保存する。
困ったときはまずログを見る、というのが本当にシンプルで効果的だと感じた一件でした。
改善例① Lambda関数のメモリ
現状では問題なくDynamoDBへのCSV投入はできているものの、リソースに無駄が発生している場合があります。
私の場合、Lambda関数のCloudWatchログを見ていると、実行ログは以下のとおりでした。
Billed Duration: 224 ms Memory Size: 3008 MB Max Memory Used: 77 MB Init Duration: 487.73 msこれは、「Lambda関数のメモリを3008MB確保しているが、実際に使用したのは77MBで、課金対象の実行時間は224msである 。」ことを示しています。
Lambda関数の使用料金はメモリ確保量と実行時間で決まるので、明らかにメモリを余分に確保しすぎています。
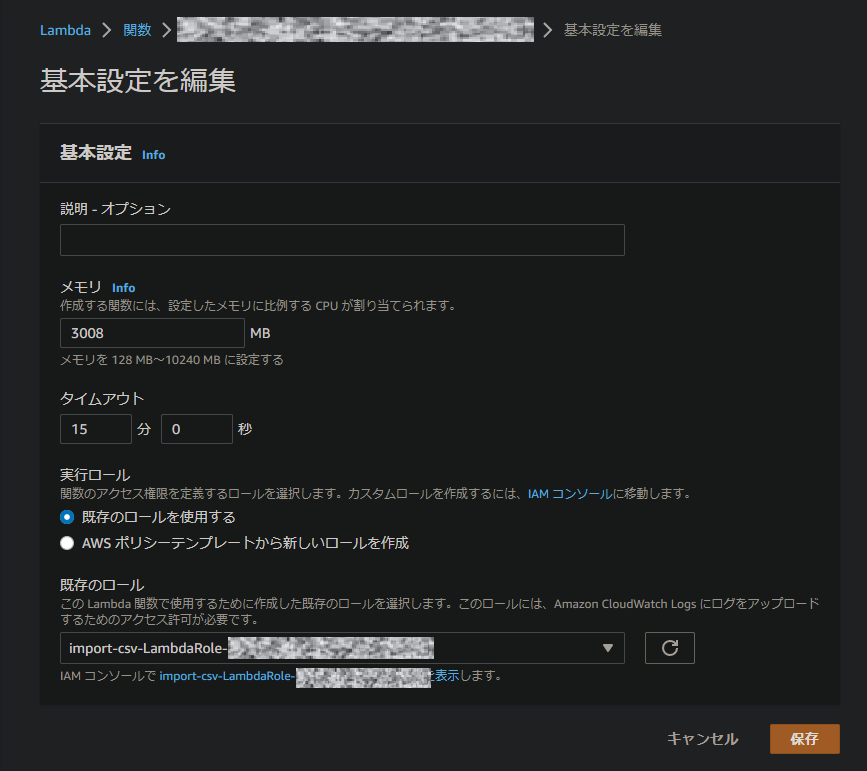
そこで、このLambda関数のメモリ確保量を128MBまで縮小します。
コンソールからLambda関数の「一般設定」→「編集」と進み、メモリを3008MBから128MBに変更します。
その後、再びDynamoDBへのCSV一括投入を試みたログがこちらです。
Billed Duration: 1489 ms Memory Size: 128 MB Max Memory Used: 77 MB Init Duration: 797.38 ms課金対象時間は1489msと、メモリ変更前の7倍程度になってしまいましたが、メモリサイズとの兼ね合いからこちらの方が安く使用できます。
Lambdaの料金はこちらのAWS公式サイトで確認できるので、実行時間と料金のバランスが丁度いいメモリサイズを選択することをお勧めします。
私の場合は128MBだと切り詰めすぎなので、512MBぐらいがちょうどいいかもしれません。
改善例② DynamoDBのキャパシティユニット(RCU, WCU)
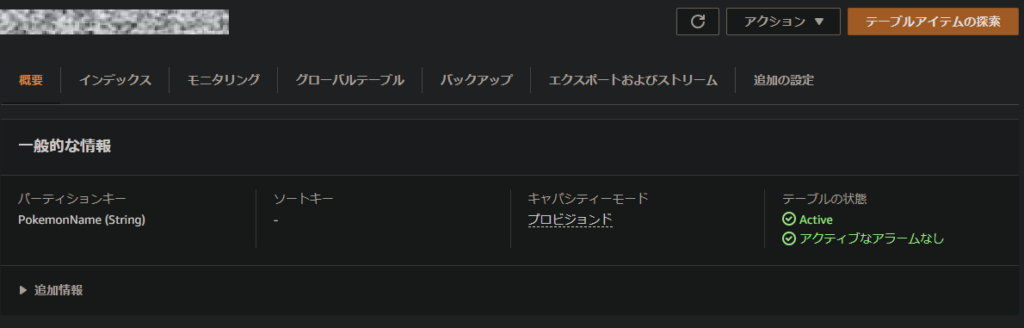
デフォルトでは、CloudFormationによって作成されるDynamoDBテーブルは、オンデマンドによる課金形態となっています。
これは、実際に使用した分だけ料金が課金される形態ですが、プロビジョンドモードよりも単価は高くなります。
DynamoDBは、プロビジョンドモードならば一定の量まではAWS無料利用枠で利用できるため(2022年3月現在)、可能な方はプロビジョンドモードに変更することをお勧めします。
無料利用枠は変更になる可能性がありますので、詳細は公式ページをご覧ください。
まとめ
いかがだったでしょうか。
今回は、DynamoDBにCSVファイルを一括投入する方法をご紹介しました。
一度作成してしまえばその後の作業が大幅に楽になるので、DynamoDBに初期データを入れたい場合は非常にお勧めの方法です。
CloudFormationの勉強にもなりますので、AWSを触って覚えるのにも良い機会になるかと思います。
是非お試しください!
KimYas

